
Journal of Computational Finance
ISSN:
1755-2850 (online)
Editor-in-chief: Christoph Reisinger
Numerical solution of the Hamilton–Jacobi–Bellman formulation for continuous-time mean–variance asset allocation under stochastic volatility
K Ma and P. A. Forsyth
Abstract
ABSTRACT
We present efficient partial differential equation (PDE) methods for continuous-time mean-variance portfolio allocation problems when the underlying risky asset follows a stochastic volatility process. The standard formulation for mean-variance optimal portfolio allocation problems gives rise to a two-dimensional nonlinear Hamilton–Jacobi–Bellman (HJB) PDE. We use a wide stencil method based on a local coordinate rotation to construct a monotone scheme. Further, by using a semi-Lagrangian timestepping method to discretize the drift term, along with an improved linear interpolation method, accurate efficient frontiers are constructed. This scheme can be shown to be convergent to the viscosity solution of the HJB equation, and the correctness of the proposed numerical framework is verified by numerical examples. We also discuss the effects on the efficient frontier of the stochastic volatility model parameters.
Introduction
1 Introduction
Consider the following prototypical asset allocation problem: an investor can choose to invest in a risk-free bond, or a risky asset, and can dynamically allocate wealth between the two assets, to achieve a predetermined criteria for the portfolio over a long time horizon. In the continuous-time mean–variance approach, risk is quantified by variance, so investors aim to maximize the expected return of their portfolios, given a risk level. Alternatively, they aim to minimize the risk level, given an expected return. As a result, mean–variance strategies are appealing due to their intuitive nature, since the results can be easily interpreted in terms of the trade-off between the risk and the expected return.
In the case where the asset follows a geometric Brownian motion (GBM), there is considerable literature on the topic (Li and Ng 2000; Bielecki et al 2005; Zhou and Li 2000; Wang and Forsyth 2010). The multi-period optimal strategy adopted in these papers is of pre-commitment type, which is not time consistent, as noted in Bjork and Murgoci (2010) and Basak and Chabakauri (2010). A comparison between time-consistent and pre-commitment strategies for continuous-time mean–variance optimization is given in Wang and Forsyth (2012). We note that since a time-consistent strategy can be constructed from a pre-commitment policy by adding a constraint (Wang and Forsyth 2012), the time-consistent strategy is suboptimal compared with the pre-commitment policy, ie, it is costly to enforce time consistency. In addition, it has been shown in Vigna (2014) that pre-commitment strategies can also be viewed as a target-based optimization, which involves minimizing a quadratic loss function. It is suggested in Vigna (2014) that this is intuitive, adaptable to investor preferences and also mean–variance efficient.
Most previous literature on pre-commitment mean–variance optimal asset allocation has been based on analytic techniques (Li and Ng 2000; Zhou and Li 2000; Bielecki et al 2005; Zhao and Ziemba 2000; Nguyen and Portait 2002). These papers have primarily employed martingale methods (Bielecki et al 2005; Zhao and Ziemba 2000; Nguyen and Portait 2002) or tractable auxiliary problems (Li and Ng 2000; Zhou and Li 2000). However, in general, if realistic constraints on portfolio selection are imposed, eg, no trading if insolvent and a maximum leverage constraint, then a fully numerical approach is required. As shown in Wang and Forsyth (2010), in the case where the risky asset follows a GBM, realistic portfolio constraints have a significant effect on the efficient frontier.
Another modeling deficiency in previous work on pre-commitment mean–variance optimal asset allocation is the common assumption that the risky asset follows a GBM. However, there is strong empirical evidence that asset return volatility is serially correlated, shocks to volatility are negatively correlated with asset returns and the conditional variance of asset returns is not constant over time. As a result, it is highly desirable to describe the risky asset with a stochastic volatility model. In this case, the standard formulation of mean–variance optimal asset allocation problems gives rise to a two-dimensional nonlinear Hamilton–Jacobi–Bellman (HJB) PDE. The objective of this paper is to develop a numerical method for the pre-commitment mean–variance portfolio selection problem when the underlying risky asset follows a stochastic volatility model.
The major contributions of the paper are the following.
- •
We develop a fully implicit, consistent, unconditionally monotone numerical scheme for the HJB equation, which arises in the embedding formulation (Zhou and Li 2000; Li and Ng 2000) of the pre-commitment mean–variance problem under our model setup. The main difficulty in designing a discretization scheme is developing a monotone approximation of the cross-derivative term in the PDE. We use the wide stencil method (Debrabant and Jakobsen 2013; Ma and Forsyth 2014) to deal with this difficulty.
- •
We construct accurate efficient frontiers by using a semi-Lagrangian time-stepping method to handle the drift term and an improved method of linear interpolation at the foot of the characteristic in the semi-Lagrangian discretization. In particular, the improved interpolation method uses the exact solution value at a single point, dramatically increasing the accuracy of the numerical results. Any type of constraint can be applied to the investment policy.
- •
We prove that the scheme developed in this paper converges to the viscosity solution of the nonlinear HJB value equation.
- •
In order to trace out the efficient frontier solution of our problem, we use two techniques: the PDE method and the hybrid (PDE–Monte Carlo) method (Tse et al 2013). We also demonstrate that the hybrid method is superior to the PDE method.
- •
We carry out several numerical experiments, and illustrate the convergence of the numerical scheme as well as the effect of modeling parameters on efficient frontiers.
The remainder of this paper is organized as follows. Section 2 describes the underlying processes and the embedding framework, and gives a formulation of an associated HJB equation and a linear PDE. In Section 3, we present the discretization of the HJB equation. In Section 4, we highlight some important implementation details of the numerical method. Numerical results are presented and discussed in Section 5.
2 Mathematical formulation
Suppose there are two assets in the market: one is a risk-free bond, and the other is a risky equity index. The dynamics of the risk-free bond follows
| (2.1) |
and an equity index follows Heston’s model (Heston 1993) under the real probability measure
| (2.2) |
where the variance of the index, , follows a mean-reverting square-root process (Cox et al 1985):
| (2.3) |
with , being increments of Wiener processes. The instantaneous correlation between and is . The market price of volatility risk is , which generates a risk premium proportional to . This assumption for the risk premium is based on Breeden’s consumption-based model (Breeden 1979), and it originates from Heston (1993). Therefore, under this setup, the market is incomplete, as trading in the risky asset and the bond cannot perfectly hedge the changes in the stochastic investment opportunity set.
An investor in this market is endowed at time zero with an initial wealth of , and they can continuously and dynamically alter the proportion of wealth invested in each asset. In addition, let denote the wealth at time , and let denote the proportion of this wealth invested in the risky asset ; consequently, denotes the fraction of wealth invested in the risk-free bond . The allocation strategy is a function of the current state, ie, . Note that in using the shorthand notations for the mapping, for the value , and the dependence on the current state is implicit. From (2.1) and (2.2), we see that the investor’s wealth process follows
| (2.4) |
2.1 Efficient frontiers and embedding methods
We assume here that the investor is guided by a pre-commitment mean–variance objective based on the final wealth . The pre-commitment mean–variance problem and its variations have been intensively studied in the literature (Li and Ng 2000; Zhou and Li 2000; Bielecki et al 2005; Zhao and Ziemba 2000; Nguyen and Portait 2002). To the best of our knowledge, there is no explicit closed-form solution for the pre-commitment mean–variance problem when the risky asset follows a stochastic volatility process along with leverage constraints.
To simplify our notation, we define for a state space. Let and denote the expectation and variance of the terminal wealth conditional on the state and the control . Given a risk level , an investor desires their expected terminal wealth to be as large as possible. Equivalently, given an expected terminal wealth , they wish the risk to be as small as possible. That is, they desire to find controls that generate Pareto optimal points. For notational simplicity, let and . The problem is rigorously formulated as follows.
Define the achievable mean–variance objective set as
| (2.5) |
where is the set of admissible strategies, and denote the closure of by .
Definition 2.1.
A point is Pareto mean–variance optimal if there exists no admissible strategy such that
| (2.6) |
where at least one of the inequalities in the equation is strict. We denote by the set of Pareto mean–variance optimal points. Note that .
Although the above definition is intuitive, determining the points in requires the solution of a multi-objective optimization problem, involving two conflicting criteria. A standard scalarization method can be used to combine the two criteria into an optimization problem with a single objective. In particular, for each point , and for an arbitrary scalar , we define the set of points to be
| (2.7) |
from which a point on the efficient frontier can be derived. The set of points on the efficient frontier is then defined as
| (2.8) |
Note that there is a difference between the set of all Pareto mean–variance optimal points (see Definition 2.1) and the efficient frontier (2.8) (Tse et al 2014). In general,
but the converse may not hold if the achievable mean–variance objective set (2.5) is not convex. In this paper, we restrict our attention to constructing (2.8).
Due to the presence of the variance term in (2.7), a dynamic programming principle cannot be directly applied to solve this problem. To overcome this difficulty, we make use of the main result in Li and Ng (2000), Zhou and Li (2000) and Tse et al (2014), which essentially involves the embedding technique. This result is summarized in Theorem 2.3.
Assumption 2.2.
We assume that is a non-empty subset of and that there exists a positive scalarization parameter such that .
Theorem 2.3.
The embedded mean–variance objective set is defined by
| (2.9) |
where
| (2.10) |
Theorem 2.3 states that the mean and variance of are embedded in a scalarization optimization problem, with the objective function being . Noting that
| (2.13) |
and that we can ignore the constant term for the purposes of minimization, we then define the value function
| (2.14) |
Theorem 2.3 implies that there exists a such that, for a given positive , a control that minimizes (2.7) also minimizes (2.14). Dynamic programming can then be directly applied to (2.14) to determine the optimal control .
The procedure for determining the points on the efficient frontier is as follows. For a given value of , the optimal strategy is determined by solving for the value function problem (2.14). Once this optimal policy is known, it is then straightforward to determine a point on the frontier. Varying traces out a curve in the plane (see details in Section 4.2). Consequently, the numerical challenge is to solve for the value function (2.14). More precisely, the above procedure for constructing the efficient frontier generates points that are in the set . As pointed out in Tse et al (2014), the set may contain spurious points, ie, points that are not in . For example, when the original problem is nonconvex, spurious points can be generated. An algorithm for removing spurious points is discussed in Tse et al (2014). The set of points in with the spurious points removed generates all points in . Dang et al (2016) also discusses the convergence of finitely sampled to the efficient frontier.
Remark 2.4 (Range of ).
As noted in Dang et al (2016), a solution to (2.10) generally exists for all . However, we know from the above discussion that some of these solutions may be spurious. In some cases, we can use financial reasoning to reduce the range of so that obvious spurious points are eliminated. We discuss this further in Section 4.2.1.
2.2 The value function problem
Following standard arguments, the value function , (2.14) is the viscosity solution of the HJB equation
| (2.15) |
on the domain , and with the terminal condition
| (2.16) |
Remark 2.5.
In one of our numerical tests, we allow to become unbounded, which may occur when (Wang and Forsyth 2010). However, although as , we must have as , ie, the amount invested in the risky asset converges to zero as . This is required in order to ensure that the no-bankruptcy boundary condition is satisfied (Wang and Forsyth 2010). As a result, we can then formally eliminate the problem with unbounded control by using as the control, and assume remains bounded (see details in Wang and Forsyth (2010)).
2.3 The expected wealth problem
2.3.1 The PDE formulation
Given the solution for the value function (2.14), with the optimal control , we then need to determine the expected value , denoted as
| (2.17) |
Then, , is given from the solution to the following linear PDE:
| (2.18) |
with the initial condition , where is obtained from the solution of the HJB equation (2.15).
2.3.2 The hybrid (PDE–Monte Carlo) method
Alternatively, given the stored control determined from the solution of (2.15), we can directly estimate by using a Monte Carlo method, based on solving the stochastic differential equations (SDEs) (2.3) and (2.4). The details of the SDE discretization are given in Section 4.2. This hybrid (PDE–Monte Carlo) method was originally proposed in Tse et al (2013).
2.4 Allowable portfolios
In order to obtain analytical solutions, many previous papers typically make assumptions that allow for the possibility of unbounded borrowing and bankruptcy. Moreover, these models assume a bankrupt investor can still keep on trading. The ability to continue trading even though the value of an investor’s wealth is negative is highly unrealistic. In this paper, we enforce the condition that the wealth value remains in the solvency regions by applying certain boundary conditions to the HJB equation (Wang and Forsyth 2008). Thus, bankruptcy is prohibited, ie,
We will also assume that there is a leverage constraint, ie, the investor must select an asset allocation satisfying
which can be interpreted as the maximum leverage condition, and is a known positive constant with typical value in . Thus, the control set
Note that when the risk premium (2.2) is positive, as in our case, it is not optimal to short the risky asset, since we have only a single risky asset in our portfolio. In some circumstances, it may be optimal to short the risky asset. This will be discussed in Section 3.1.3.
3 Numerical discretization of the Hamilton–Jacobi–Bellman equation
3.1 Localization
We will assume that the discretization is posed on a bounded domain for computational purposes. The discretization is applied to the localized finite region . Asymptotic boundary conditions will be imposed at and , which are compatible with a monotone numerical scheme.
3.1.1 The localization of
The proper boundary on needs to be specified to be compatible with the corresponding SDE (2.3), which has a unique solution (Feller 1951). If , the so-called Feller condition holds, and is unattainable. If the Feller condition is violated, , then is an attainable boundary but is strongly reflecting (Feller 1951). The appropriate boundary condition can be obtained by setting into (2.15). That is,
| (3.1) |
and the equation degenerates to a linear PDE. On the lower boundary , the variance and the risk premium vanish, according to (2.4), so that the wealth return is always the risk-free rate . The control value vanishes in the degenerate equation (3.1), and we can simply define , which we need in the estimation of using the Monte Carlo simulation. In this case, since the equity asset has zero volatility with drift rate , the distinction between the equity asset and risk-free asset is meaningless.
The validity of this boundary condition is intuitively justified by the fact that the solution to the SDE for is unique, such that the behavior of at the boundary is determined by the SDE itself, and, hence, the boundary condition is determined by setting in (2.15). A formal proof that this boundary condition is correct is given in Ekström and Tysk (2010). If the boundary at is attainable, then this boundary behavior serves as a boundary condition and guarantees uniqueness in the appropriate function spaces. However, if the boundary is non-attainable, then the boundary behavior is not needed to guarantee uniqueness, but it is nevertheless very useful in a numerical scheme.
On the upper boundary , is set to zero. Thus, the boundary condition on is set to
| (3.2) |
The optimal control at is determined by solving (3.2). This boundary condition can be justified by noting that, as , the diffusion term in the direction in (2.15) becomes large. In addition, the initial condition (2.16) is independent of . As a result, we expect that
where and are constants, and, hence, at .
3.1.2 The localization for
We prohibit the possibility of bankruptcy by requiring (Wang and Forsyth 2010), so, on , (2.15) reduces to
| (3.3) |
3.1.3 Alternative localization for
is the viscosity solution of the HJB equation (2.15). Recall that the initial condition for problem (2.14) is
For a fixed gamma, we define the discounted optimal embedded terminal wealth at time , denoted by , as
| (3.5) |
It is easy to verify that is a global minimum state of the value function . Consider the state , , and the optimal strategy such that , . Under , the wealth is all invested in the risk-free bond without further rebalancing from time . As a result, the wealth will accumulate to with certainty, ie, the optimal embedded terminal wealth is achievable. By (2.14), we have
| (3.6) |
Since the value function is the expectation of a nonnegative quantity, it can never be less than zero. Hence, the exact solution for the value function problem at the special point must be zero. This result holds for both the discrete and continuous rebalancing case. For the formal proof, we refer the reader to Dang and Forsyth (2014a).
Consequently, the point is a Dirichlet boundary , and information for is not needed. In principle, we can restrict the domain to . However, it is computationally convenient to restrict the size of the computational domain to be , which avoids the issue of having a moving boundary, at a very small additional cost. Note that the optimal control will ensure that without any need to enforce this boundary condition. This will occur, as we assume continuous rebalancing. This effect, that , is also discussed in Vigna (2014). It is interesting to note that, in the case of discrete rebalancing or jump diffusions, it is optimal to withdraw cash from the portfolio if it is ever observed that . However, Bauerle and Grether (2015) show that if the market is complete, then it is never optimal to withdraw cash from the portfolio. This is also discussed in Cui et al (2012) and Dang and Forsyth (2014a).
In the case of an incomplete market, such as discrete rebalancing or jump diffusions, if we do not allow the withdrawing of cash from the portfolio, then the investor has an incentive to lose money if , as pointed out in Cui et al (2012). In this rather perverse situation, it may be optimal to short the risky asset, so that the admissible set in this case would be , with .
We have verified, experimentally, that restricting the computational domain to gives the same results as the domain , , with asymptotic boundary condition (3.4).
Remark 3.1 (Significance of ).
If we assume that initially (otherwise, the problem is trivial if we allow cash withdrawals), then the optimal control will ensure that for all . Hence, continuous-time mean–variance optimization is “time consistent in efficiency” (Cui et al 2012). Another interpretation is that continuous-time mean–variance optimization is equivalent to minimizing the quadratic loss with respect to the wealth target (Vigna 2014).
Remark 3.2 (Significance of ).
3.2 Discretization
In the following section, we discretize (2.15) over a finite grid in the space . Define a set of nodes in the direction and in the direction. Denote the th time step by , , with . Let be the approximate solution of (2.15) at .
It will be convenient to define
We assume that there is a mesh discretization parameter such that
| (3.7) |
where , , , , are constants independent of .
In the following sections, we will give the details of the discretization for a reference node , , .
3.2.1 The wide stencil
We need a monotone discretization scheme in order to guarantee convergence to the desired viscosity solution (Barles and Souganidis 1991). We remind the reader that seemingly reasonable non-monotone discretizations can converge to the incorrect solution (Pooley et al 2003). Due to the cross-derivative term in (2.15), however, a classic finite difference method cannot produce such a monotone scheme. Since the control appears in the cross-derivative term, it will not be possible (in general) to determine a grid spacing or global coordinate transformation that eliminates this term. We will adopt the wide stencil method developed in Ma and Forsyth (2014) to discretize the second derivative terms. Suppose we discretize (2.15) at grid node for a fixed control. For a fixed , consider a virtual rotation of the local coordinate system clockwise by the angle :
| (3.8) |
That is, in the transformed coordinate system is obtained by using the following matrix multiplication:
| (3.9) |
We denote the rotation matrix in (3.9) as . This rotation operation will result in a zero correlation in the diffusion tensor of the rotated system. Under this grid rotation, the second-order terms in (2.18) are, in the transformed coordinate system ,
| (3.10) |
where is the value function in the transformed coordinate system, and
| (3.11) |
The diffusion tensor in (3.10) is diagonally dominant with no off-diagonal terms; consequently, a standard finite difference discretization for the second partial derivatives results in a monotone scheme. The rotation angle depends on the grid node and the control; therefore, it is impossible to rotate the global coordinate system by a constant angle and build a grid over the entire space . The local coordinate system rotation is only used to construct a virtual grid, which overlays the original mesh. We have to approximate the values of on our virtual local grid using an interpolant on the original mesh. To keep the numerical scheme monotone, must be a linear interpolation operator. Moreover, to keep the numerical scheme consistent, we need to use the points on our virtual grid, whose Euclidean distances are from the central node, where is the mesh discretization parameter (3.7). This results in a wide stencil method, since the relative stencil length increases as the grid is refined ( as ). For more details, we refer the reader to Ma and Forsyth (2014).
The drift term in (3.13) is discretized by a standard backward or forward finite differencing discretization, depending on the sign of . Overall, the discretized form of the linear operator is then denoted by :
| (3.14) |
where is the discretization parameter, and the superscript in indicates that the discretization depends on the control . Note that , and are given in (3.11), and the presence of , , is due to the discretization of the second derivative terms. is the th column of the rotation matrix.
3.2.2 Semi-Lagrangian time-stepping scheme
When , (2.15) degenerates, with no diffusion in the direction. As a result, we will discretize the drift term in (2.15) by a semi-Lagrangian time-stepping scheme in this section. Initially introduced by Douglas and Russell (1982) and Pironneau (1982) for atmospheric and weather numerical prediction problems, semi-Lagrangian schemes can effectively reduce the numerical problems arising from convection dominated equations.
First, we define the Lagrangian derivative by
| (3.15) |
which is the rate of change of along the characteristic defined by the risky asset fraction through
| (3.16) |
We can then rewrite (3.12) as
| (3.17) |
Solving (3.16) backward in time from and for a fixed gives the point at the foot of the characteristic
| (3.18) |
which, in general, is not on the PDE grid. We use the notation to denote an approximation of the value , which is obtained by linear interpolation to preserve monotonicity. The Lagrangian derivative at a reference node is then approximated by
| (3.19) |
where denotes that depends on the control through (3.18). For the details of the semi-Lagrangian time-stepping scheme, we refer the reader to Chen and Forsyth (2007).
Finally, by using the implicit time-stepping method, combining the expressions (3.14) and (3.19), the HJB equation (3.17) at a reference point is then discretized as
| (3.20) |
where is the discrete control set. There is no simple analytic expression that can be used to minimize the discrete equation (3.20), and we need to discretize the admissible control set and perform a linear search. This guarantees that we find the global maximum of (3.20), since the objective function has no known convexity properties. If the discretization step for the controls is also , where is the discretization parameter, then this is a consistent approximation (Wang and Forsyth 2008).
3.3 Matrix form of the discrete equation
| Notation | Domain |
|---|---|
| The upper boundary | |
| The upper boundary | |
| The lower boundary | |
| The lower boundary | |
Our discretization is summarized as follows. The domains are defined in Table 1. For the case , we need to use a wide stencil based on a local coordinate rotation to discretize the second derivative terms. We also need to use the semi-Lagrangian time-stepping scheme to handle the drift term . The HJB equation is discretized as (3.20), and the optimal in this case is determined by solving (3.20). For the case , the HJB equation degenerates to (3.2). In this case, the drift term is also handled by the semi-Lagrangian time-stepping scheme. With vanishing cross-derivative term, the degenerate linear operator can be discretized by a standard finite difference method. The corresponding discretized form is given in Section 3.3.1. The value for case is obtained by the asymptotic solution (3.4), and the optimal is set to zero. At the lower boundaries and , the HJB equation degenerates to a linear equation. The wide stencil and the semi-Lagrangian time-stepping scheme may require the value of the solution at a point outside the computational domain, denoted as . Details on how to handle this case are given in Section 4.3. From the discretization (3.20), we can see that the measure of converges to zero as . Last, fully implicit time stepping is used to ensure unconditional monotonicity of our numerical scheme. Fully implicit time stepping requires the solution of highly nonlinear algebraic equations at each time step. For the applications addressed in Forsyth and Labahn (2007), an efficient method for solving the associated nonlinear algebraic systems makes use of a policy iteration scheme. We refer the reader to Huang et al (2012) and Forsyth and Labahn (2007) for the details of the policy iteration algorithm.
It is convenient to use a matrix form to represent the discretized equations for computational purposes. Let be the approximate solution of (2.15) at , , and , and form the solution vector
| (3.21) |
It will sometimes be convenient to use a single index when referring to an entry of the solution vector
Let . We define the matrix , where
| (3.22) |
is an indexed set of controls, and each is in the set of admissible controls. is the entry on the th row and th column of the discretized matrix . We also define a vector of boundary conditions .
For the case , where the Dirichlet boundary condition (3.4) is imposed, we then have
| (3.23) |
and
| (3.24) |
For the case , the differential operator degenerates, and the entries are constructed from the discrete linear operator (see (3.32)). That is,
| (3.25) |
For the case , we need to use the values at the following four off-grid points , , in (3.14), and we denote those values by , respectively. Let be indexes such that
| (3.26) |
with linear interpolation weights
When , using linear interpolation, values at the four points , , are approximated as follows:
| (3.27) |
For linear interpolation, we have that
Then, inserting (3.27) into (3.14), the entries on th row are specified. When we use , we directly use its asymptotic solution (3.4). Thus, we need to define the vector to facilitate the construction of the matrix form in this situation when we use a point in the domain :
| (3.28) |
where and are defined in (3.11). As a result, for the case ,
| (3.29) |
where is defined in (3.14).
The final matrix form of the discretized equations is then
| (3.31) |
where is the discretized control set .
Remark 3.3.
Note that , and depend only on .
3.3.1 The discrete linear operator
With vanishing cross-derivative term, the degenerate linear operator (3.13) can be discretized by a standard finite difference method. The degenerate linear operators in (3.1)–(3.3) are approximated as the discrete form
| (3.32) |
where , , and are defined as follows:
| (3.33) |
The coefficients , , and are all nonnegative, and they are compatible with a monotone scheme. On the upper boundary , the coefficients and degenerate to zero; on the lower boundary , and are set to zero. On the lower boundary , , , and , .
3.4 Convergence to the viscosity solution
Assumption 3.4.
Provided that the original HJB satisfies Assumption 3.4, we can show that the numerical scheme (3.31) is stable, consistent and monotone, and then the scheme converges to the unique and continuous viscosity solution (Barles and Souganidis 1991). We give a brief overview of the proof as follows.
- •
Stability: from the formation of matrix in (3.24), (3.25) and (3.29), it is easily seen that (3.31) has positive diagonals and non-positive off-diagonals, and the th row sum for the matrix is
(3.34) where ; hence, the matrix is diagonally dominant, and thus it is an matrix (Varga 2009). We can then easily show that the numerical scheme is stable by a straightforward maximum analysis, as in d’Halluin et al (2004).
- •
Monotonicity: to guarantee monotonicity, we use a wide stencil to discretize the second derivative terms in the discrete linear operator (3.14) (see proof in Ma and Forsyth (2014)). Note that using linear interpolation to compute (3.19) in the semi-Lagrangian time-stepping scheme also ensures monotonicity.
- •
Consistency: a simple Taylor series verifies consistency. As noted in Section 4.3, we may shrink the wide stencil length to avoid using points below the lower boundaries. We can use the same proof as in Ma and Forsyth (2014) to show that this treatment retains local consistency. Since we have either simple Dirichlet boundary conditions, or the PDE at the boundary is the limit from the interior, we need only use the classical definition of consistency here (see proof in Ma and Forsyth (2014)). The only case where the point (3.19) in the semi-Lagrangian time-stepping scheme is outside the computational domain is through the upper boundary , where the asymptotic solution (3.4) is used. Thus, unlike the semi-Lagrangian time-stepping scheme in Chen and Forsyth (2007), we do not need the more general definition of consistency (Barles and Souganidis 1991) to handle the boundary data.
3.5 Policy iteration
Our numerical scheme requires the solution of highly nonlinear algebraic equations (3.31) at each time step. We use the policy iteration algorithm (Forsyth and Labahn 2007) to solve the associated algebraic systems. For the details of the algorithm, we refer the reader to Forsyth and Labahn (2007) and Huang et al (2012). Regarding the convergence of the policy iteration, since the matrix (3.31) is an matrix and the control set is a finite set, it is easy to show that the policy iteration is guaranteed to converge (Forsyth and Labahn 2007).
4 Implementation details
4.1 Complexity
Examination of the algorithm for solving discrete equations (3.31) reveals that each time step requires the following steps.
- •
In order to solve the local optimization problems at each node, we perform a linear search to find the minimum for . Thus, with a total of nodes, this gives a complexity for solving the local optimization problems at each time step.
- •
We use a preconditioned Bi-CGSTAB iterative method for solving the sparse matrix at each policy iteration. The time complexity of solving the sparse matrix is (Saad 2003). Note that, in general, we need to reconstruct the data structure of the sparse matrix for each iteration.
Assuming that the number of policy iterations is bounded as the mesh size tends to zero, which is in fact observed in our experiments, the complexity of the time advance is thus dominated by the solution of the local optimization problems. Finally, the total complexity is .
4.2 The efficient frontier
In order to trace out the efficient frontier solution of problem (2.7), we proceed in the following way. Pick an arbitrary value of and solve problem (2.14), which determines the optimal control . There are then two methods to determine the quantities of interest , namely the PDE method and the hybrid (PDE–Monte Carlo) method. We will compare the performance of these methods in the numerical experiments.
4.2.1 The PDE method
For a fixed , given and obtained solving the corresponding equations (2.15) and (2.18) at the initial time with and , we can then compute the corresponding pair , where . That is,
which gives us a single candidate point . Repeating this for many values of gives us a set of candidate points.
We are effectively using the parameter to trace out the efficient frontier. From Theorem 2.3, we have that . If , the investor is infinitely risk averse, and invests only the risk-free bond; hence, in this case, the smallest possible value of is
| (4.1) |
In practice, the interesting part of the efficient frontier is in the range . Finally, the efficient frontier is constructed from the upper left convex hull of (Tse et al 2014) to remove spurious points. In our case, however, it turns out that all the points are on the efficient frontier, and there are no spurious points, if .
4.2.2 The hybrid (PDE–Monte Carlo) discretization
In the hybrid method, given the stored optimal control from solving the HJB PDE (2.15), are then estimated by Monte Carlo simulations. We use the Euler scheme to generate the Monte Carlo simulation paths of the wealth (2.4), and an implicit Milstein scheme to generate the Monte Carlo simulation paths of the variance process (2.3). Starting with and , the Euler scheme for the wealth process (2.4) is
| (4.2) |
and the implicit Milstein scheme of the variance process (2.3) (Kahl and Jäckel 2006) is
| (4.3) |
where and are standard normal variables with correlation . Note that this discretization scheme will result in strictly positive paths for the variance process if (Kahl and Jäckel 2006). For the cases where this bound does not hold, it will be necessary to modify (4.3) to prevent problems with the computation of . For instance, whenever drops below zero, we could use the Euler discretization
| (4.4) |
where . Lord et al (2010) reviews a number of similar remedies to get around the problem of when becomes negative and concludes that the simple fix (4.4) works best.
4.3 Outside the computational domain
To make the numerical scheme consistent in a wide stencil method (Section 3.2.1), the stencil length needs to be increased to use the points beyond the nearest neighbors of the original grid. Therefore, when solving the PDE in a bounded region, the numerical discretization may require points outside the computational domain. When a candidate point we use is outside the computational region at the upper boundaries, we can directly use its asymptotic solution (3.4). For a point outside the upper boundary , the asymptotic solution is specified by (3.4). For a point outside the upper boundary , by the implication of the boundary condition on , we have
| (4.5) |
However, we have to take special care when we may use a point below the lower boundaries or , because (2.15) is defined over . The possibility of using points below the lower boundaries only occurs when the node falls in a possible region close to the lower boundaries
as discussed in Ma and Forsyth (2014). We use the algorithm proposed in Ma and Forsyth (2014) so that only information within the computational domain is used. That is, when one of the four candidate points , , (3.14) is below the lower boundaries, we then shrink its corresponding distance (from the reference node ) to , instead of the original distance . This simple treatment ensures that all data required is within the domain of the HJB equation. It is straightforward to show that this discretization is consistent (Ma and Forsyth 2014).
In addition, due to the semi-Lagrangian time stepping (Section 3.2.2), we may need to evaluate the value of an off-grid point (3.18). This point may be outside the computational domain through the upper boundary (the only possibility). When this situation occurs, the asymptotic solution (3.4) is used.
4.4 An improved linear interpolation scheme
When solving the value function problem (2.15) or the expected value problem (2.18) on a computational grid, it is required to evaluate and , respectively, at points other than a node of the computational grid. This is especially important when using semi-Lagrangian time stepping. Hence, interpolation must be used. As mentioned earlier, to preserve the monotonicity of the numerical schemes, linear interpolation for an off-grid node is used in our implementation. Dang and Forsyth (2014b) introduce a special linear interpolation scheme applied along the direction to significantly improve the accuracy of the interpolation in a two-dimensional impulse control problem. We modify this algorithm in our problem setup.
We then take advantage of the results in Section 3.1.3 to improve the accuracy of the linear interpolation. Assume that we want to proceed from time step to , and that we want to compute , where is neither a grid point in the direction nor the special value , and is defined in (3.5). Further, assume that for some grid points and . For presentation purposes, let and . An improved linear interpolation scheme along the direction for computing is shown in Algorithm 1. Note that the interpolation along the direction is a plain linear interpolation; thus, we only illustrate the interpolation algorithm in the direction.
Algorithm 1 Improved linear interpolation scheme along the direction for the function value problem.
1: if or then
2: set , , and
3: else
4: if then
5: set , , and
6: else
7: set , , and
8: end if
9: end if
10: Apply linear interpolation to and to compute
Following the same line of reasoning used for the function value problem, we have that
By using this result, a similar method to Algorithm 1 can be used to improve the accuracy of linear interpolation when computing the expected value .
Remark 4.1.
For the discretization of the expected value problem (2.18), we still use semi-Lagrangian time stepping to handle the drift term . Since it may be necessary to evaluate at points other than a node of the computational grid, we need to use linear interpolation.
5 Numerical experiments
In this section, we present the numerical results of the solution of (2.15) applied to the continuous-time mean–variance portfolio allocation problem. In our problem, the risky asset (2.2) follows the Heston model. The parameter values of the Heston model used in our numerical experiments are taken from Aït-Sahalia and Kimmel (2007) and based on empirical calibration from the Standard & Poor’s 500 (S&P 500) and VIX index data sets during 1990 to 2004 (under the real probability measure). Table 2 lists the Heston model parameters, and Table 3 lists the parameters of the mean–variance portfolio allocation problem.
| 5.07 | 0.0457 | 0.48 | 0.767 | 1.605 |
| Investment horizon | 10 |
| Risk-free rate | 0.03 |
| Leverage constraint | 2 |
| Initial wealth | 100 |
| Initial variance | 0.0457 |
For all the experiments, unless otherwise noted, the details of the grid, the control set and time step refinement levels used are given in Table 4.
| Refinement | Time steps | nodes | nodes | nodes |
|---|---|---|---|---|
| 0 | 160 | 112 | 57 | 8 |
| 1 | 320 | 223 | 113 | 15 |
| 2 | 640 | 445 | 225 | 29 |
| 3 | 1280 | 889 | 449 | 57 |
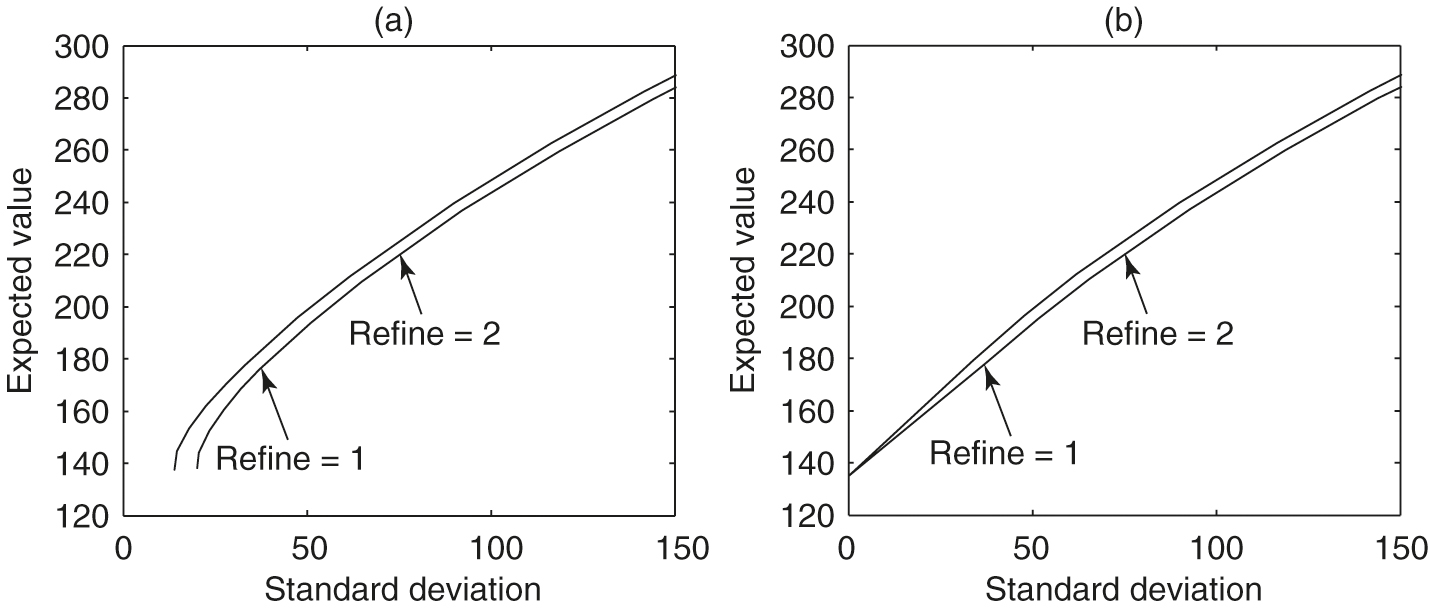
5.1 Effects of the improved interpolation scheme for the PDE method
In this subsection, we discuss the effects on numerical results of the linear interpolation scheme described in Section 4.4. We plot expected values against standard deviation, since both variables have the same units. Figure 1(a) illustrates the numerical efficient frontiers obtained using standard linear interpolation. It is clear that the results are very inaccurate for small standard deviations. It appears that the numerical methods were not able to construct the known point on the exact efficient frontier
This trivial case corresponds to the case where (4.1), and the investor invests only in the risk-free bond and not in the risky asset. However, as shown in Figure 1(a), in this special case, the standard deviation obtained by the numerical scheme using standard linear interpolation is far from the exact solution.
Figure 1(b) shows the numerical efficient frontiers obtained with the improved linear interpolation scheme, where Algorithm 1 is utilized. It is obvious that the numerical efficient frontiers obtained with the improved linear interpolation scheme are more reasonable, especially for the small standard deviation region. In particular, the special point at which the variance is zero is now approximated accurately. This result illustrates the importance of using the optimal embedded terminal wealth and its function value for linear interpolation in constructing accurate numerical efficient frontiers. In all our numerical experiments in the following, the improved linear interpolation scheme is used.

5.2 Convergence analysis
In this section, we illustrate the convergence of our numerical scheme and compare the performance of two methods, namely the PDE method (Section 4.2.1) and the hybrid method (4.2.2), for constructing the mean–variance frontier under our model setup.
Figure 2 shows that the mean standard deviation efficient frontiers computed by both the PDE method and the hybrid method converge to the same frontier as the computational grid is refined. Our numerical results demonstrate that the hybrid frontiers in general converge faster to the limit results than the pure PDE solutions. This same phenomenon was observed in Tse et al (2013). As shown in Figure 2, the frontiers obtained by the hybrid method are almost identical for refinement levels 1 and 2. Note that for both methods the optimal control is always computed by solving the HJB PDEs.
| Refine | Mean | Change | Ratio | SD | Change | Ratio |
|---|---|---|---|---|---|---|
| 0 | 207.1434 | 71.3924 | ||||
| 1 | 210.4694 | 3.3260 | 65.5090 | 5.88336 | ||
| 2 | 212.1957 | 1.7263 | 1.92 | 62.0862 | 3.42288 | 1.72 |
| 3 | 213.1481 | 0.95238 | 1.81 | 60.4738 | 1.61237 | 2.12 |
| Refine | Mean | Change | Ratio | SD | Change | Ratio |
|---|---|---|---|---|---|---|
| 0 | 212.2993 | 56.6128 | ||||
| 1 | 213.2077 | 0.908 | 57.7652 | 1.152 | ||
| 2 | 213.7573 | 0.550 | 1.65 | 58.2987 | 0.534 | 2.16 |
| 3 | 213.9903 | 0.233 | 2.36 | 58.5253 | 0.227 | 2.35 |
| Refine | Mean | Change | Ratio | SD | Change | Ratio |
|---|---|---|---|---|---|---|
| 0 | 320.5139 | 217.0009 | ||||
| 1 | 325.5443 | 5.030 | 212.1886 | 4.812 | ||
| 2 | 328.2670 | 2.723 | 1.85 | 209.8434 | 2.345 | 2.05 |
| 3 | 329.8172 | 1.550 | 1.76 | 208.9045 | 0.939 | 2.50 |

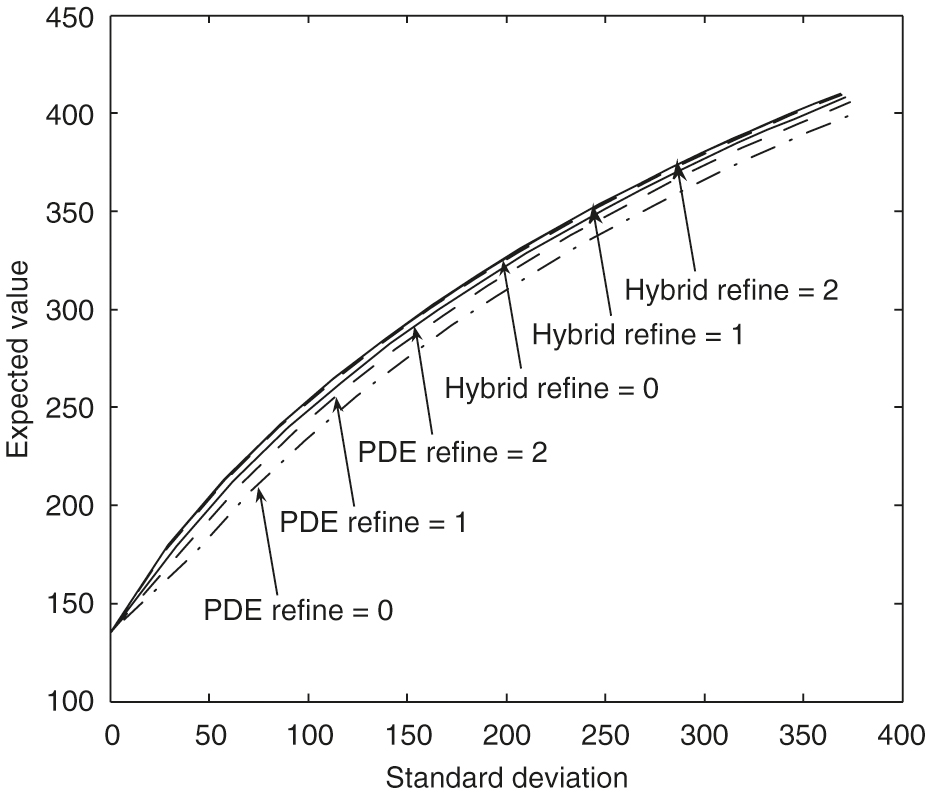
The same time steps are used in both the PDE method and Monte Carlo simulations for each refinement level. For example, the frontiers labeled with “” for both methods in Figure 2 use the time steps specified as “Refinement 1” in Table 4. To achieve small sampling error in Monte Carlo simulations, simulations are performed for the numerical experiments. The standard error in Figure 2 can then be estimated. For example, consider a point on the frontier with a large standard deviation value that is about . For the expected value of , the sample error is approximately , which could be negligible in Figure 2.
We will verify our conclusion by examining several specific points on these efficient frontiers in Figure 2. Tables 5 and 6 show computed means and standard deviations for different refinement levels when . The numerical results indicate first-order convergence is achieved for both the PDE method and the hybrid method. In this case, our numerical results demonstrate that the hybrid frontiers converge faster to the limit results than the PDE solutions. Tables 7 and 8 show computed means and standard deviations for different refinement levels when . The numerical results indicate first-order convergence is achieved for the PDE method. In this case, our numerical results also demonstrate that the hybrid frontiers converge faster to the limit results than the PDE solutions. However, the convergence ratio for the hybrid method is erratic. As we noted before, in this case, the sample error for the estimate of the mean value is about , which makes the convergence ratio estimates in Table 8 unreliable. To decrease the sample error to, for example, , the number of simulation paths would have to increase to , which is unaffordable in terms of the computational cost. Note that in the case , with the small standard deviation, the sample error for the mean is about .
| Refine | Mean | Change | Ratio | SD | Change | Ratio |
|---|---|---|---|---|---|---|
| 0 | 329.4411 | 206.0875 | ||||
| 1 | 330.5172 | 1.076 | 206.8351 | 0.748 | ||
| 2 | 330.7066 | 0.189 | 5.68 | 207.1958 | 0.361 | 2.07 |
| 3 | 331.2820 | 0.575 | 0.33 | 207.3707 | 0.175 | 2.06 |

Remark 5.1 (Efficiency of the hybrid method).
We remind the reader that for both the hybrid and PDE methods, the same (computed) control is used. The more rapid convergence of the hybrid method is simply due to a more accurate estimate of the expected quantities (with a known control). This result is somewhat counterintuitive, since it suggests that a low accuracy control can be used to generate high accuracy expected values. We also observe this from the fact that a fairly coarse discretization of the admissible set generates fairly accurate solutions.
5.3 Sensitivity of efficient frontiers
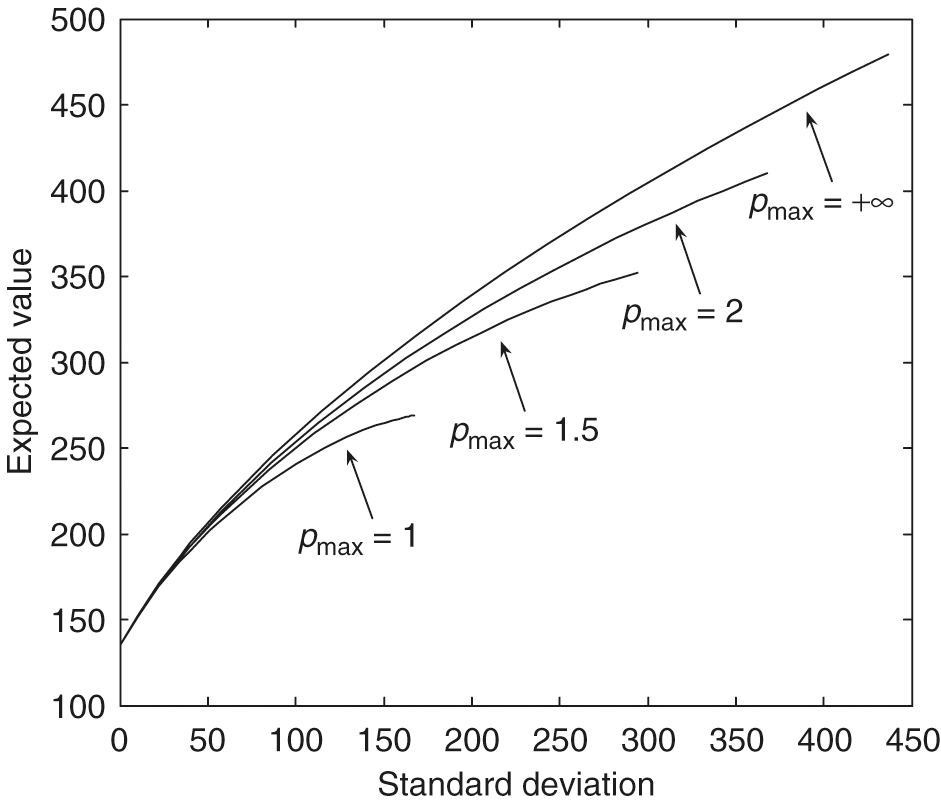
In this subsection, we show some numerical sensitivity analysis for the major market parameters, namely the leverage constraints , the market risk , the mean reversion level for the variance , the volatility of the variance , the correlation between the risky asset and the variance, and the mean reversion speed . In our numerical tests, the corresponding frontiers are generated as the market parameter of interest changes, and the values of the remaining parameters are fixed and listed in Tables 2 and 3. We use the hybrid method with discretization level 2.


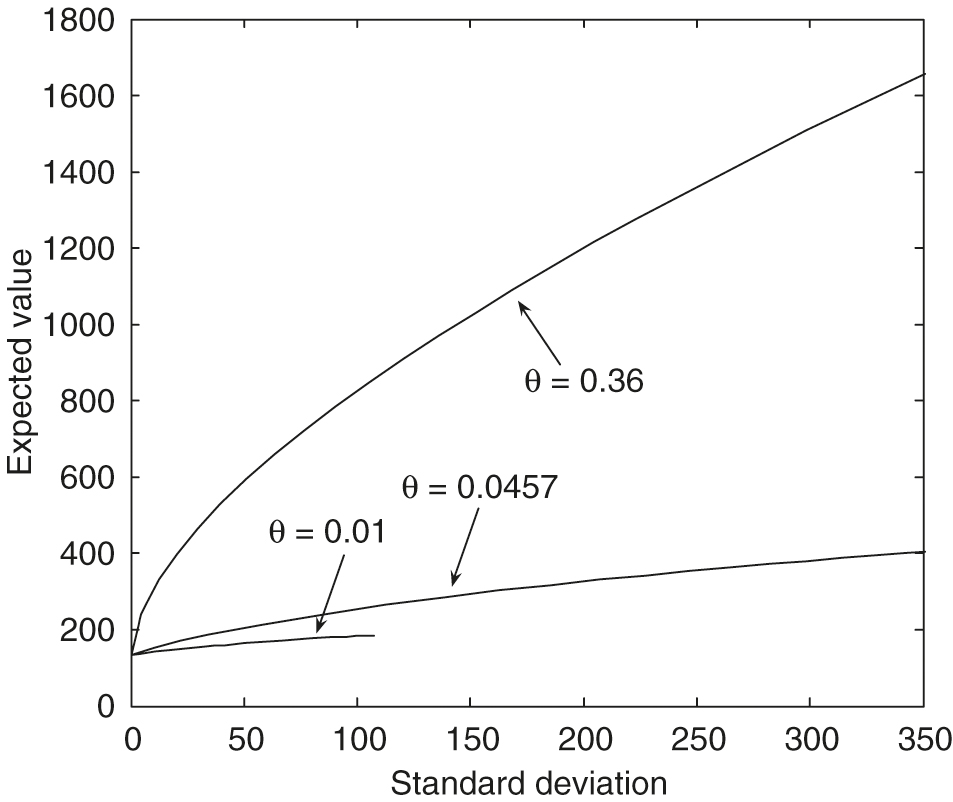
As observed in Figure 3, with , we can see that larger values of the leverage constraints result in much more dominant efficient frontiers. From Figure 4, with , we can see that larger values of result in much more dominant efficient frontiers. The maximal standard deviation point () on the efficient frontier with is only about , which is much smaller than those with larger values. From Figure 5, , we can see that larger values of the mean reversion level for the variance result in much more dominant efficient frontiers. The maximal standard deviation point () on the efficient frontier with is only about , which is much smaller than those with larger values. From Figure 6, , we can see that larger values of the volatility of the variance result in slightly more dominant, efficient frontiers in general. In particular, these efficient frontiers in the large standard deviation region with different values are almost identical.

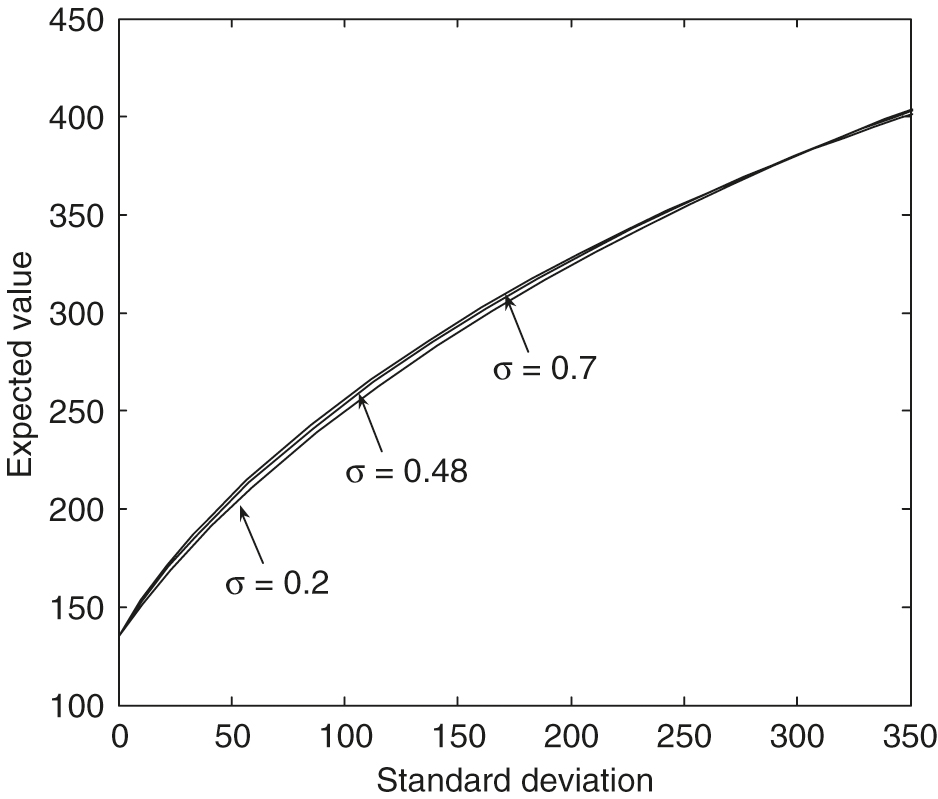

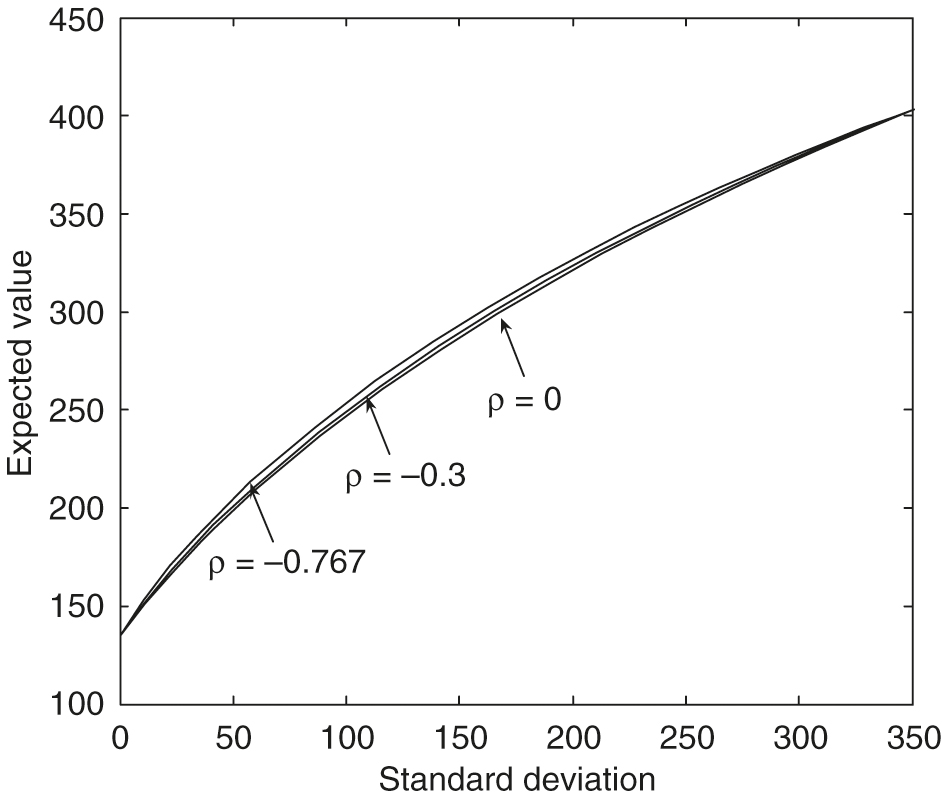

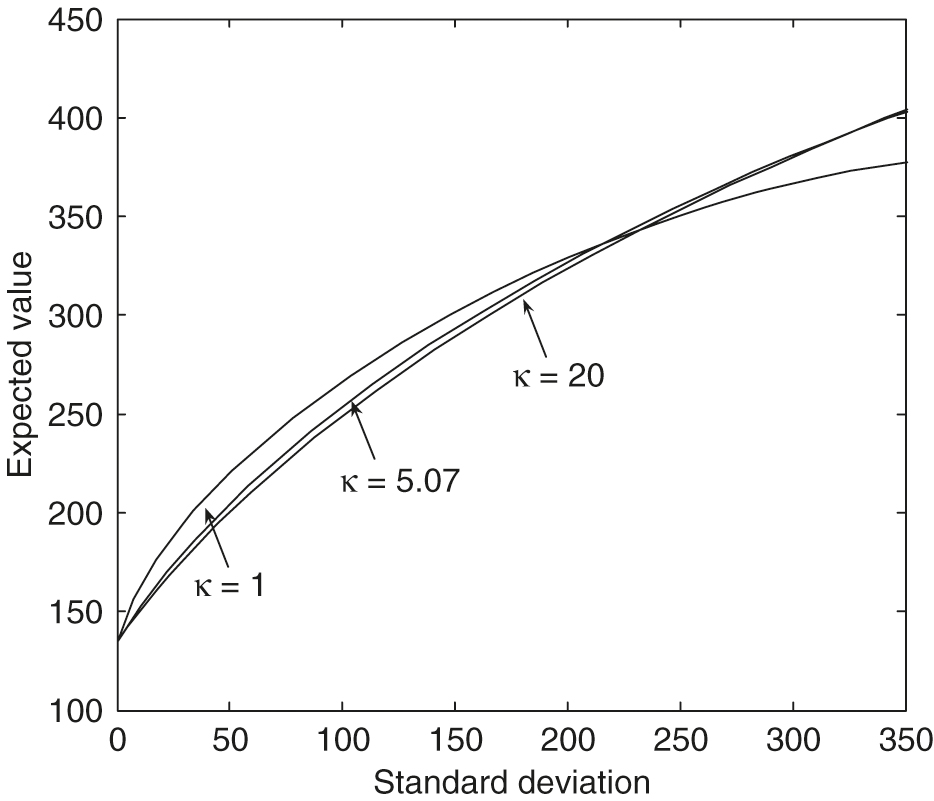
However, from Figure 7, with , we can see that an increase in the correlation produces frontiers with a slightly smaller expected value for a given standard deviation. These efficient frontiers in the large standard deviation region with different values are almost identical. The effect of the values on the efficient frontiers is more complex. From Figure 8, , in the small standard deviation region, an increase in produces frontiers with a smaller expected value for a given standard deviation. However, when the standard deviation increases to about , the larger values of gradually result in more significant dominant efficient frontiers.
5.4 Comparison between constant volatility and stochastic volatility cases
In this paper, the risky asset follows the stochastic volatility model ((2.2) and (2.3)). In this section, we will compare the constant volatility and stochastic volatility cases in terms of mean–variance efficiency for the continuous-time pre-commitment mean–variance problem. With a constant volatility, the risky asset is governed by the following GBM process:
| (5.1) |
To compare this with the stochastic volatility case in Table 2, the constant volatility is set to , and the risky return over the risk-free rate is set to , which has the same mean premium of the volatility risk as the stochastic volatility model (2.2). This then corresponds to the case where the variance in (2.2) is fixed to the mean reversion level . The remaining mean–variance problem parameters are the same as those listed in Table 3.

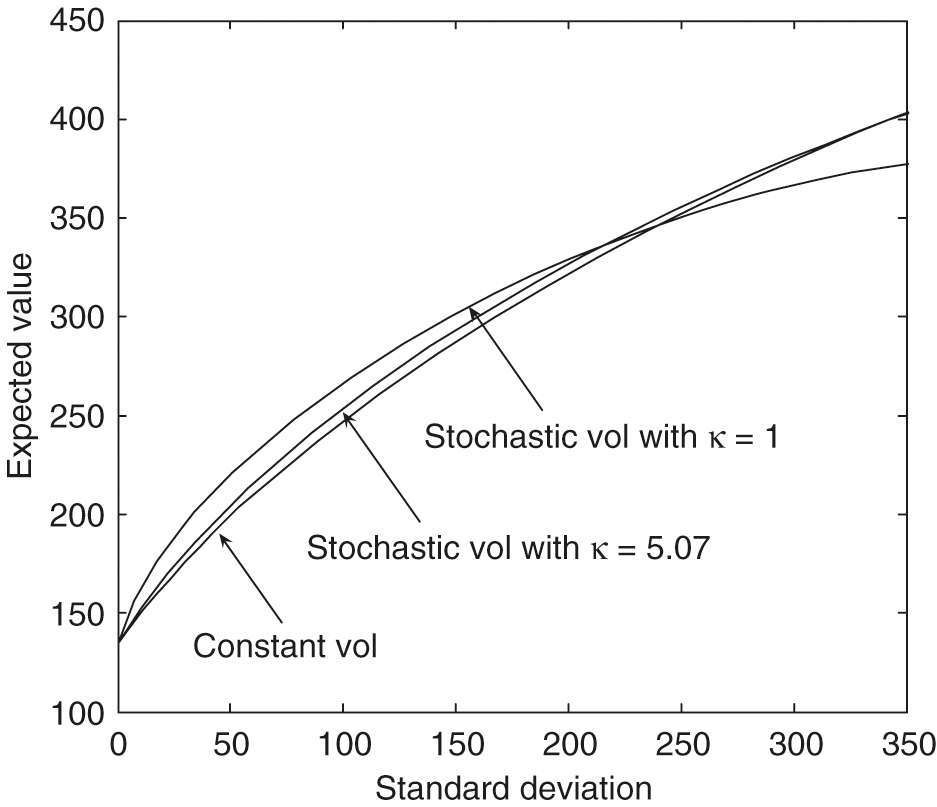
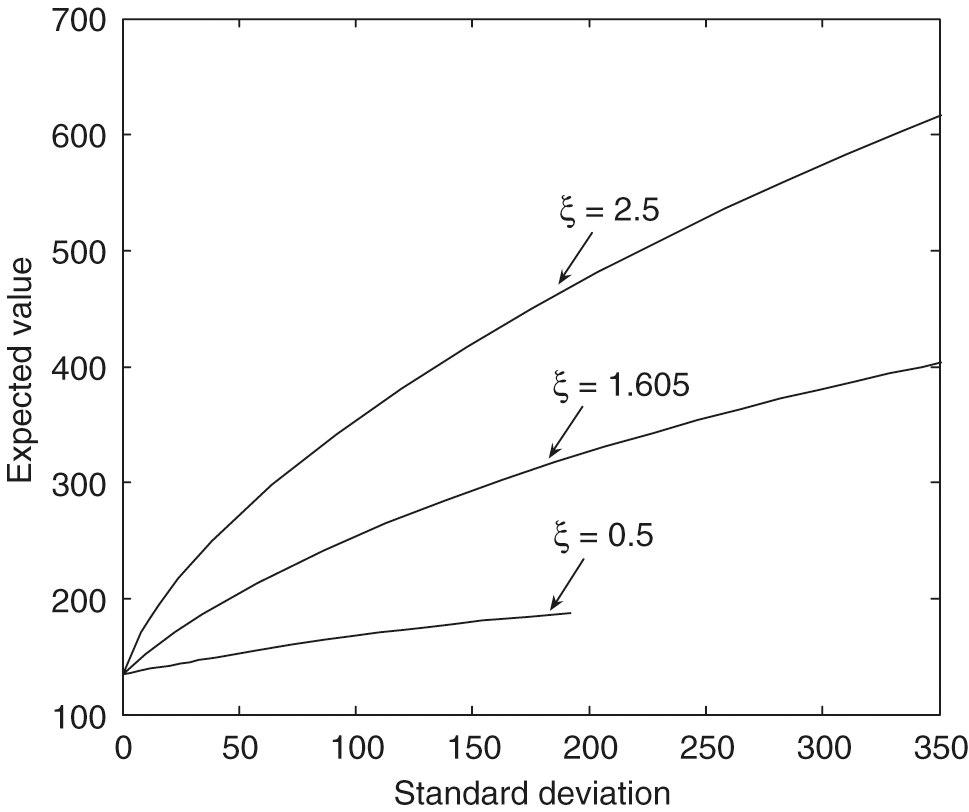
Figure 9 illustrates the fact that the efficient frontiers produced by using the stochastic volatility slightly dominate the curve produced by the constant volatility model. With the Heston model’s parameters in Table 2, we may conclude that the efficient frontier produced by the constant volatility is a good approximation of the frontier generated by the stochastic volatility model. From Figure 9, however, we see that if the mean reversion speed is set to a small value, eg, 1, in the stochastic volatility case, the efficient frontiers computed using a constant volatility model will be considerably different from those computed using the stochastic volatility model. The quantity is measured in years and is related to the time over which a volatility shock dissipates. Specifically, the half-life of a volatility shock is .
Finally, using the portfolio allocation strategy that is precomputed and stored from the constant volatility case, we then carry out a Monte Carlo simulation where the risky asset follows the stochastic volatility model. We then compare the results using this approximate control, with the optimal control computed using the full stochastic volatility model. From Table 9, we can see that the mean–variance pairs computed using the optimal strategy are very close to the strategy computed using the GBM approximation. Based on several tests, a good heuristic guideline is that if , then the GBM control is a good approximation to the exact optimal control.
| Control process | Price process | Mean | SD | Mean | SD |
|---|---|---|---|---|---|
| GBM | GBM | 209.50 | 59.68 | 330.09 | 213.01 |
| GBM | SV | 212.68 | 58.42 | 329.13 | 207.23 |
| SV | SV | 213.99 | 58.53 | 331.28 | 207.37 |
6 Conclusion
In this paper, we develop an efficient fully numerical PDE approach for the pre-commitment continuous-time mean–variance asset allocation problem when the risky asset follows a stochastic volatility model. We use the wide stencil method (Ma and Forsyth 2014) to overcome the main difficulty in designing a monotone approximation. We show that our numerical scheme is monotone, consistent and -stable. Hence, the numerical solution is guaranteed to converge to the unique viscosity solution of the corresponding HJB PDE, assuming that the HJB PDE satisfies a strong comparison property. Further, using semi-Lagrangian time stepping to handle the drift term, along with an improved method of linear interpolation, allows us to compute accurate efficient frontiers. When tracing out the efficient frontier solution of our problem, we demonstrate that the hybrid (PDE–Monte Carlo) method (Tse et al 2013) converges faster than the pure PDE method. Similar results are observed in Tse et al (2013). Finally, if the mean reversion time is small compared with the investment horizon , then a constant volatility GBM approximation to the stochastic volatility process gives a very good approximation to the optimal strategy.
Declaration of interest
The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the paper. This work was supported by the Bank of Nova Scotia and the Natural Sciences and Engineering Research Council of Canada.
References
- Aït-Sahalia, Y., and Kimmel, R. (2007). Maximum likelihood estimation of stochastic volatility models. Journal of Financial Economics 83(2), 413–452 (http://doi.org/b3c4dg).
- Barles, G., and Souganidis, P. E. (1991). Convergence of approximation schemes for fully nonlinear second order equations. Asymptotic Analysis 4(3), 271–283.
- Basak, S., and Chabakauri, G. (2010). Dynamic mean–variance asset allocation. Review of Financial Studies 23(8), 2970–3016 (http://doi.org/cqnc3g).
- Bauerle, N., and Grether, S. (2015). Complete markets do not allow free cash flow streams. Mathematical Methods of Operations Research 81, 137–145 (http://doi.org/bkpx).
- Bielecki, T. R., Jin, H., Pliska, S. R., and Zhou, X. Y. (2005). Continuous-time mean–variance portfolio selection with bankruptcy prohibition. Mathematical Finance 15(2), 213–244 (http://doi.org/cj3svf).
- Bjork, T., and Murgoci, A. (2010). A general theory of Markovian time inconsistent stochastic control problems. SSRN Working Paper (http://doi.org/fzcfp2).
- Breeden, D. T. (1979). An intertemporal asset pricing model with stochastic consumption and investment opportunities. Journal of Financial Economics 7(3), 265–296 (http://doi.org/c8t9tr).
- Chen, Z. L., and Forsyth, P. A. (2007). A semi-Lagrangian approach for natural gas storage valuation and optimal operation. SIAM Journal on Scientific Computing 30(1), 339–368 (http://doi.org/bqnf83).
- Cox, J. C., Ingersoll, J., Jonathan, E., and Ross, S. A. (1985). A theory of the term structure of interest rates. Econometrica: Journal of the Econometric Society 53(2), 385–407 (http://doi.org/cbb2pm).
- Cui, X., Li, D., Wang, S., and Zhu, S. (2012). Better than dynamic mean–variance: time inconsistency and free cash flow stream. Mathematical Finance 22(2), 346–378 (http://doi.org/dvr3gq).
- Dang, D. M., and Forsyth, P. A. (2014a). Better than pre-commitment mean–variance portfolio allocation strategies: a semi-self-financing Hamilton–Jacobi–Bellman equation approach. European Journal on Operational Research 132, 271–302 (http://doi.org/bkpk).
- Dang, D. M., and Forsyth, P. A. (2014b). Continuous time mean–variance optimal portfolio allocation under jump diffusion: a numerical impulse control approach. Numerical Methods for Partial Differential Equations 30(2), 664–698 (http://doi.org/bkpz).
- Dang, D. M., Forsyth, P. A., and Li, Y. (2016). Convergence of the embedded mean–variance optimal points with discrete sampling. Numerische Mathematik 132(2), 271–302 (http://doi.org/bkp2).
- Debrabant, K., and Jakobsen, E. (2013). Semi-Lagrangian schemes for linear and fully non-linear diffusion equations. Mathematics of Computation 82(283), 1433–1462 (http://doi.org/bkp3).
- d’Halluin, Y., Forsyth, P. A., and Labahn, G. (2004). A penalty method for American options with jump diffusion processes. Numerische Mathematik 97(2), 321–352 (http://doi.org/d5sn5v).
- Douglas, J. J., and Russell, T. F. (1982). Numerical methods for convection-dominated diffusion problems based on combining the method of characteristics with finite element or finite difference procedures. SIAM Journal on Numerical Analysis 19(5), 871–885 (http://doi.org/dzghv5).
- Ekström, E., and Tysk, J. (2010). The Black–Scholes equation in stochastic volatility models. Journal of Mathematical Analysis and Applications 368(2), 498–507 (http://doi.org/drbjzd).
- Feller, W. (1951). Two singular diffusion problems. Annals of Mathematics 54(1), 173–182 (http://doi.org/bvf5m4).
- Forsyth, P. A., and Labahn, G. (2007). Numerical methods for controlled Hamilton–Jacobi–Bellman PDEs in finance. The Journal of Computational Finance 11(2), 1–44 (http://doi.org/bkp4).
- Heston, S. L. (1993). A closed-form solution for options with stochastic volatility with applications to bond and currency options. Review of Financial Studies 6(2), 327–343 (http://doi.org/fg525s).
- Huang, Y., Forsyth, P. A., and Labahn, G. (2012). Combined fixed point and policy iteration for HJB equations in finance. SIAM Journal on Numerical Analysis 50(4), 1849–1860 (http://doi.org/bkp5).
- Kahl, C., and Jäckel, P. (2006). Fast strong approximation Monte Carlo schemes for stochastic volatility models. Quantitative Finance 6(6), 513–536 (http://doi.org/cqtf4z).
- Li, D., and Ng, W.-L. (2000). Optimal dynamic portfolio selection: multiperiod mean–variance formulation. Mathematical Finance 10(3), 387–406 (http://doi.org/dt4h2f).
- Lord, R., Koekkoek, R., and Dijk, D. V. (2010). A comparison of biased simulation schemes for stochastic volatility models. Quantitative Finance 10(2), 177–194 (http://doi.org/bjjn3n).
- Ma, K., and Forsyth, P. A. (2014). An unconditionally monotone numerical scheme for the two factor uncertain volatility model. IMA Journal on Numerical Analysis (forthcoming).
- Nguyen, P., and Portait, R. (2002). Dynamic asset allocation with mean variance preferences and a solvency constraint. Journal of Economic Dynamics and Control 26(1), 11–32 (http://doi.org/dgkfgc).
- Pironneau, O. (1982). On the transport-diffusion algorithm and its applications to the Navier-Stokes equations. Numerische Mathematik 38(3), 309–332 (http://doi.org/dz4dc9).
- Pooley, D. M., Forsyth, P. A., and Vetzal, K. R. (2003). Numerical convergence properties of option pricing PDEs with uncertain volatility. IMA Journal of Numerical Analysis 23(2), 241–267 (http://doi.org/bq6t6z).
- Saad, Y. (2003). Iterative Methods for Sparse Linear Systems. SIAM (http://doi.org/bq25g6).
- Tse, S. T., Forsyth, P. A., Kennedy, J. S., and Windcliff, H. (2013). Comparison between the mean–variance optimal and the mean-quadratic-variation optimal trading strategies. Applied Mathematical Finance 20(5), 415–449 (http://doi.org/bkp6).
- Tse, S. T., Forsyth, P. A., and Li, Y. (2014). Preservation of scalarization optimal points in the embedding technique for continuous time mean variance optimization. SIAM Journal on Control and Optimization 52(3), 1527–1546 (http://doi.org/bkp7).
- Varga, R. S. (2009). Matrix Iterative Analysis, Volume 27. Springer.
- Vigna, E. (2014). On efficiency of mean–variance based portfolio selection in defined contribution pension schemes. Quantitative Finance 14(2), 237–258 (http://doi.org/bkp8).
- Wang, J., and Forsyth, P. A. (2008). Maximal use of central differencing for Hamilton–Jacobi–Bellman PDEs in finance. SIAM Journal on Numerical Analysis 46(3), 1580–1601 (http://doi.org/ffw87k).
- Wang, J., and Forsyth, P. A. (2010). Numerical solution of the Hamilton–Jacobi–Bellman formulation for continuous time mean variance asset allocation. Journal of Economic Dynamics and Control 34(2), 207–230 (http://doi.org/d2s8c8).
- Wang, J., and Forsyth, P. A. (2012). Comparison of mean variance like strategies for optimal asset allocation problems. International Journal of Theoretical and Applied Finance 15(2), 1250014 (http://doi.org/bhwk).
- Zhao, Y., and Ziemba, W. T. (2000). Mean–variance versus expected utility in dynamic investment analysis. Working Paper, University of British Columbia.
- Zhou, X. Y., and Li, D. (2000). Continuous-time mean–variance portfolio selection: a stochastic LQ framework. Applied Mathematics and Optimization 42(1), 19–33 (http://doi.org/b6r9zv).
Only users who have a paid subscription or are part of a corporate subscription are able to print or copy content.
To access these options, along with all other subscription benefits, please contact info@risk.net or view our subscription options here: http://subscriptions.risk.net/subscribe
You are currently unable to print this content. Please contact info@risk.net to find out more.
You are currently unable to copy this content. Please contact info@risk.net to find out more.
Copyright Infopro Digital Limited. All rights reserved.
As outlined in our terms and conditions, https://www.infopro-digital.com/terms-and-conditions/subscriptions/ (point 2.4), printing is limited to a single copy.
If you would like to purchase additional rights please email info@risk.net
Copyright Infopro Digital Limited. All rights reserved.
You may share this content using our article tools. As outlined in our terms and conditions, https://www.infopro-digital.com/terms-and-conditions/subscriptions/ (clause 2.4), an Authorised User may only make one copy of the materials for their own personal use. You must also comply with the restrictions in clause 2.5.
If you would like to purchase additional rights please email info@risk.net








